




Blog, Network Cabling
Scale-Up vs. Scale-Out vs Scale-Across: What Are the Differences For AI Infrastructure

Apr
With the rapid development of the AI industry, the demand for training and data storage is also gradually increasing. As AI models continue to expand and become more complex, expanding the existing network architecture in a reasonable and efficient way becomes important. Scale-Up vs. Scale-Out vs Scale-Across are the most common mainstream solutions at present. These three methods approach the problem from three dimensions: improving single-node performance, expanding cluster scale, and integrating resources across data centers. This article will introduce these expansion methods in detail, hoping to help you find the most suitable option after reading, and also provide a clear direction for the selection of network equipment, optical modules, and cabling solutions in the future.
Table of contents
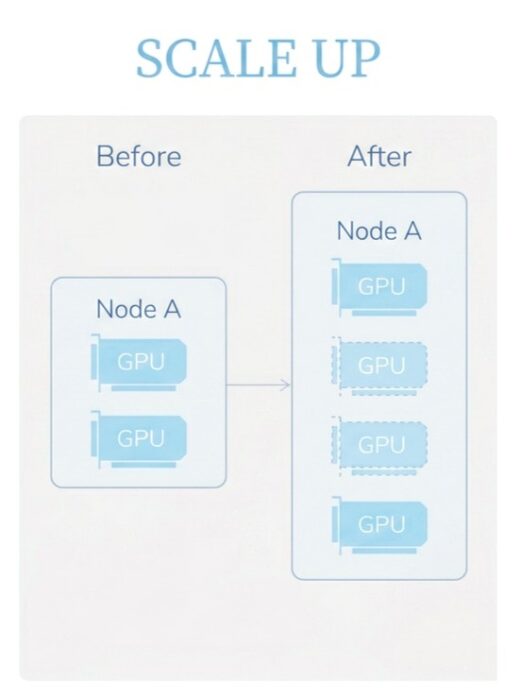
What is Scale-Up
Scale-Up is essentially a vertical expansion method. It focuses on adding more resources to an existing system to reach the expected performance level. Inside a single server, more computing resources are continuously added, such as increasing the number of GPUs, expanding memory capacity, and improving internal interconnect bandwidth. In this way, one server is built into a high-density, high-performance computing node. In AI training scenarios, this usually appears as deploying 8 GPUs, 16 GPUs, or even more in one server, and connecting these GPUs through high-speed interconnect technology into a unified computing domain, making it logically close to a single large GPU.
The key to Scale-Up lies in the communication method between GPUs. Traditional PCIe has gradually become a bottleneck in bandwidth and latency, so higher-performance interconnect technologies have become the main choice, such as NVLink. NVLink connects GPUs directly to the motherboard and is designed for AI model training like LLM, enabling fast communication between GPUs without passing through other devices. At the same time, NVLink uses multiple parallel links to expand bandwidth and significantly reduce communication overhead.
Advantages and Limitations
Scale-Up vs. Scale-Out, The advantage of Scale-Up is very low communication latency and very high bandwidth utilization. Because all computing resources are inside one machine, data does not need to go through complex network protocol stacks. But its limitation is also clear. The expansion limit depends on the physical design of a single server, including power supply, cooling, and motherboard structure. As far as a system failure occurs, the consequence only affects that particular node. The problem is overcome through further optimizations and updates by vendors. For example, NVSwitch upgrades the point-to-point NVLink architecture to a full-mesh design, improving GPU communication and reducing latency. Nevertheless, the drawback of such a solution lies in its expense, especially in the case of scaling up the system; the costs increase dramatically. Moreover, there is only a limited set of ecosystem choices due to technology monopolies.
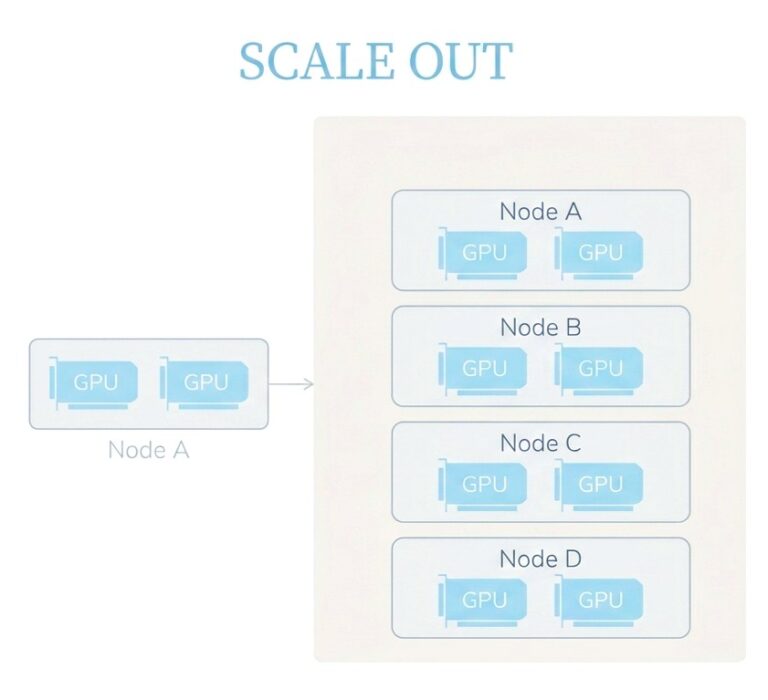
What is Scale-Out
Scale-Out is a horizontal expansion method. Its core idea is to build a large distributed computing cluster by adding more server nodes. Each server works as an independent computing unit and connects through a high-speed network to form a unified resource pool. This is currently the most common and mature expansion path in AI infrastructure. Scale-Out usually uses a Spine–Leaf topology and connects a large number of servers through high-bandwidth switches. Communication between servers depends on high-speed network protocols such as InfiniBand or Ethernet-based RoCEv2. These networks support RDMA, which allows data to bypass the CPU and operating system kernel and directly access memory between nodes, reducing latency and improving efficiency.
Advantages and Limitations
New nodes can be added directly into the existing network structure with little impact on the overall system, and it also supports scaling on demand. This gives Scale-Out strong flexibility. In terms of the hardware ecosystem, especially for Ethernet-based RoCE solutions, there is wide vendor support. Equipment such as switches, network cards, and optical modules can be selected flexibly based on budget and requirements.
However, in Scale-Up vs. Scale-Out, Scale-Out data must go through network devices, and even with InfiniBand, the latency is still higher than the GPU internal interconnect. As the cluster size grows, network complexity increases significantly. In recent years, to improve the communication efficiency of Scale-Out, new architecture ideas have been proposed. For example, DDC (Distributed Disaggregated Chassis), FSE (Fabric-Scheduled Ethernet), and DSF (Distributed Switching Fabric). These technologies extend the high-speed interconnect inside a chassis to cross-server environments, allowing large-scale clusters to achieve communication performance closer to Scale-Up.
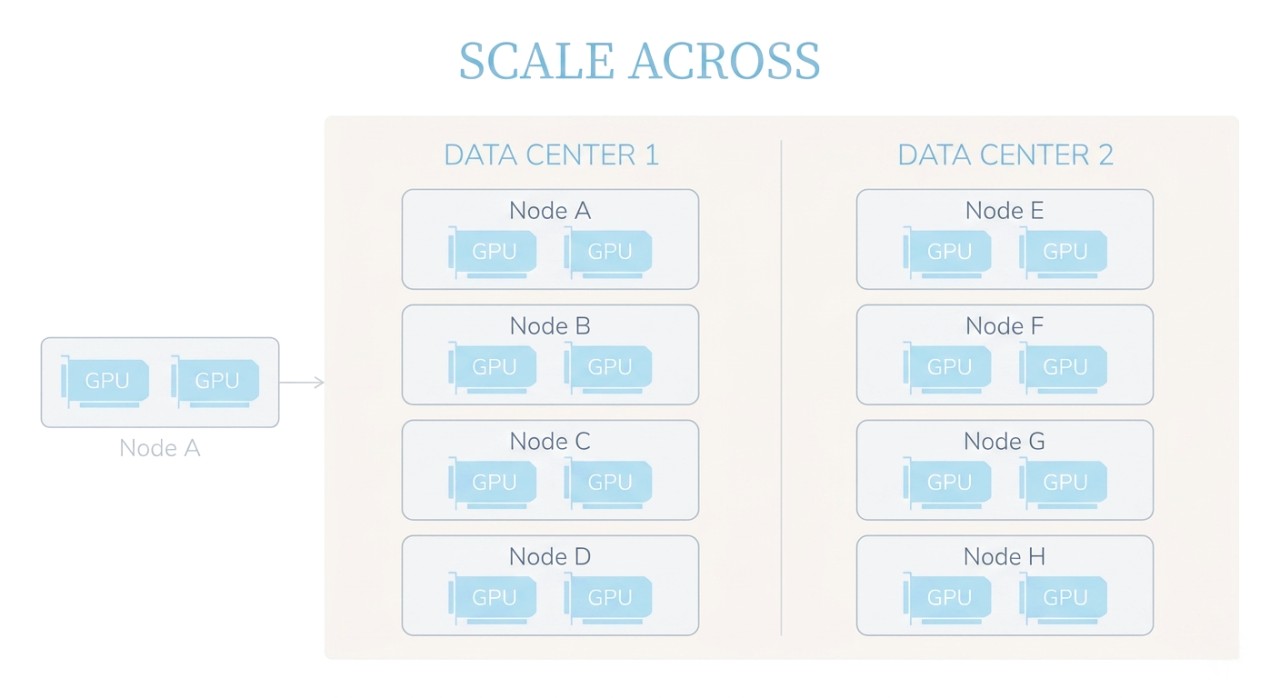
What is Scale-Across
Unlike Scale-Out, which is usually limited to one data center, Scale-Across connects computing resources from different geographic locations through data center interconnect (DCI), metro networks, or wide area networks. It connects multiple sites through optical transmission and builds a resource pool across locations. It shifts from isolated clusters to a combined view of scale-up, scale-out, and full-scale expansion. A scale-across environment includes multiple data centers (such as DC1, DC2). Each data center may already use Scale-Up or Scale-Out internally, and Scale-Across connects these clusters further to enable larger resource scheduling.
Advantages and Limitations
The advantage of Scale-Across is breaking the physical limits of a single data center while improving disaster recovery capability. When one site fails, services can move to another data center and continue running. However, its complexity and cost are also higher. Scale-Across requires a more complex network design. On one side, long-distance optical transmission is needed for interconnection. On the other side, the network must support more complex traffic scheduling, data synchronization, and fault recovery mechanisms.
Scale-Up vs. Scale-Out vs Scale-Across Overview
There are differences between these expansion methods, and they are designed for different environments. They differ in many aspects, including structure, main goal, flexibility, bandwidth, and deployment complexity. The table below helps you quickly check this information.
| Scale-Up | Scale-Out | Scale-Across | |
|---|---|---|---|
| Main Goal | Improve single-node performance | Build large-scale clusters | Integrate resources across data centers |
| Key Components / Network Conditions | NVLink / NVSwitch / High-density servers | InfiniBand / RoCEv2 / Spine-Leaf | DCI / Long-distance optical transport / WAN |
| Scalability | Limited (single-node constraint) | High | best |
| Bandwidth / Latency | Highest bandwidth, lowest latency | High bandwidth, medium latency | Limited bandwidth, high latency |
| Cost | High per node | Increases with scale | Highest |
| Deployment Complexity | Medium | High | highest |
How to make a choice for your situation
- • If you work on tasks that are mostly performed within one server, such as those involving 8 GPUs or 16 GPUs, and if your task is highly latency-sensitive, then you will benefit from the Scale-Up strategy. In this situation, it is better to improve the efficiency of GPU connections than add additional nodes. In addition, the stability of internal links becomes critical.
- • In cases where the volume of tasks that need to be completed surpasses single-server capacity and requires expansion up to dozens or hundreds of servers while preserving flexibility, the Scale-Out approach makes more sense. In such situations, you should pay attention to switch performance, networking topology design, and the stability of optical modules and cables.
- • If you have distributed resources that are located at several data centers or are limited by the power, space, and reliability of one data center, then you may choose the Scale-Across approach.
In actual engineering practice, a useful reference is that mainstream AI system design usually combines Scale-Up vs. Scale-Out into a hierarchical architecture. A common method is to first use NVLink or NVSwitch inside a single node to build a high-bandwidth GPU computing unit. Then use InfiniBand or RoCEv2 to connect multiple computing units into a large cluster.
OPTCORE currently provides a variety of interconnect solutions, including optical modules, AOC, and DAC, covering both InfiniBand and Ethernet (RoCE) scenarios. It supports different data rates ranging from 25G to 400G/800G. These products have completed compatibility testing across multiple mainstream switch and NIC environments and have been validated by many parties, making them reliable.
-

0.5~2m Generic QDD-800G-DAC Compatible 800G QSFP-DD DAC Cable
Price range: US$ 119.00 through US$ 199.00 (Excl. VAT) -

Generic QSFPDD-400G-SR8 Compatible 400GBASE-SR8 QSFP-DD 850nm 100m Transceiver
US$ 139.00 (Excl. VAT) -

OPTCORE 400G QSFP-DD AOC Cable, Generic QSFPDD-400G-AOC Compatible
-

Multimode OM4 MPO to MPO Fiber Trunk Cable, 12 Fiber, Female, Type B, LSZH
Price range: US$ 21.10 through US$ 283.50 (Excl. VAT)
FAQ
Q: Which is more suitable in Scale-Out networks, InfiniBand or RoCE?
If very low latency and high stability are required and the budget is sufficient, InfiniBand is more suitable. If you want to reuse existing Ethernet infrastructure and balance cost and performance, RoCEv2 is a more common choice, but it may require some Ethernet tuning experience.
Conclusion
From an overall view, Scale-Up vs. Scale-Out vs Scale-Across are not alternatives but layered expansion paths. Scale-Up improves single-server efficiency and utilization. Scale-Out builds large distributed GPU clusters and expands horizontally. Scale-Across works as a newer method for cross-region resource scheduling. How to use them and where to use them depends on what fits your current network situation, and often requires combining all three approaches.
Read more
- InfiniBand vs. RoCE: Understanding the Differences For Artificial Intelligence Data Center
- NVLink vs. PCIe: Understanding The Differences
- NVIDIA A100 vs H100 vs L40S vs A6000: A Detailed Comparison